5 Basic Operations
Let’s start off by creating a new R script and loading tidyverse:
library(tidyverse)Clear everything to make sure there’s nothing leftover in our environment
rm(list = ls())5.1 Data pipelines
Dplyr makes it easy to “chain” functions together using the pipe operator %>%. The following diagram illustrates the general concept of pipes where data flows from one pipe to another until all the processing is completed.
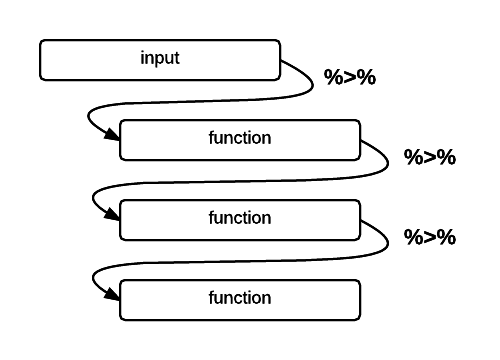
The syntax of the pipe operator %>% might appear unusual at first, but once you get used to it you’ll start to appreciate its power and flexibility.
5.2 Dataset
We’re using a dataset of flight departures from Houston in 2011.
| Filename | Description |
|---|---|
| flights.csv | Flight departures from Houston in 2011 |
| weather.csv | Hourly weather |
| planes.csv | Metadata for planes |
| airports.csv | Metadata for airports |
We’re going to use the readr package which provides improved functions for reading datasets from files. Instead of the usual read.csv() function, we’ll use the read_csv() function from readr.
flights <- read_csv("https://raw.githubusercontent.com/altaf-ali/tidydata_tutorial/master/data/flights.csv")
weather <- read_csv("https://raw.githubusercontent.com/altaf-ali/tidydata_tutorial/master/data/weather.csv")
planes <- read_csv("https://raw.githubusercontent.com/altaf-ali/tidydata_tutorial/master/data/planes.csv")
airports <- read_csv("https://raw.githubusercontent.com/altaf-ali/tidydata_tutorial/master/data/airports.csv")Now let’s examine the dataset
flights# A tibble: 227,496 x 14
date hour minute dep arr dep_delay arr_delay
<dttm> <int> <int> <int> <int> <int> <int>
1 2011-01-01 12:00:00 14 0 1400 1500 0 -10
2 2011-01-02 12:00:00 14 1 1401 1501 1 -9
3 2011-01-03 12:00:00 13 52 1352 1502 -8 -8
4 2011-01-04 12:00:00 14 3 1403 1513 3 3
5 2011-01-05 12:00:00 14 5 1405 1507 5 -3
6 2011-01-06 12:00:00 13 59 1359 1503 -1 -7
7 2011-01-07 12:00:00 13 59 1359 1509 -1 -1
8 2011-01-08 12:00:00 13 55 1355 1454 -5 -16
9 2011-01-09 12:00:00 14 43 1443 1554 43 44
10 2011-01-10 12:00:00 14 43 1443 1553 43 43
# ... with 227,486 more rows, and 7 more variables: carrier <chr>,
# flight <int>, dest <chr>, plane <chr>, cancelled <int>, time <int>,
# dist <int>weather# A tibble: 8,723 x 14
date hour temp dew_point humidity pressure visibility wind_dir
<date> <int> <dbl> <dbl> <int> <dbl> <dbl> <chr>
1 2011-01-01 0 59.0 28.9 32 29.86 10 NNE
2 2011-01-01 1 57.2 28.4 33 29.88 10 NNE
3 2011-01-01 2 55.4 28.4 36 29.93 10 NNW
4 2011-01-01 3 53.6 28.4 38 29.94 10 North
5 2011-01-01 4 NA NA NA 29.99 10 NNW
6 2011-01-01 5 NA NA NA 30.02 10 North
7 2011-01-01 6 53.1 17.1 24 30.05 10 North
8 2011-01-01 7 53.1 16.0 23 30.07 10 North
9 2011-01-01 8 54.0 18.0 24 30.09 10 North
10 2011-01-01 9 55.4 17.6 23 30.09 10 NNE
# ... with 8,713 more rows, and 6 more variables: wind_dir2 <int>,
# wind_speed <dbl>, gust_speed <dbl>, precip <dbl>, conditions <chr>,
# events <chr>planes# A tibble: 2,853 x 9
plane year mfr model no.eng no.seats speed
<chr> <int> <chr> <chr> <int> <int> <int>
1 N576AA 1991 MCDONNELL DOUGLAS DC-9-82(MD-82) 2 172 NA
2 N557AA 1993 MARZ BARRY KITFOX IV 1 2 NA
3 N403AA 1974 RAVEN S55A NA 1 60
4 N492AA 1989 MCDONNELL DOUGLAS DC-9-82(MD-82) 2 172 NA
5 N262AA 1985 MCDONNELL DOUGLAS DC-9-82(MD-82) 2 172 NA
6 N493AA 1989 MCDONNELL DOUGLAS DC-9-82(MD-82) 2 172 NA
7 N477AA 1988 MCDONNELL DOUGLAS DC-9-82(MD-82) 2 172 NA
8 N476AA 1988 MCDONNELL DOUGLAS DC-9-82(MD-82) 2 172 NA
9 N504AA NA AUTHIER ANTHONY P TIERRA II 1 2 NA
10 N565AA 1987 MCDONNELL DOUGLAS DC-9-83(MD-83) 2 172 NA
# ... with 2,843 more rows, and 2 more variables: engine <chr>, type <chr>airports# A tibble: 3,376 x 7
iata airport city state country lat
<chr> <chr> <chr> <chr> <chr> <dbl>
1 00M Thigpen Bay Springs MS USA 31.95376
2 00R Livingston Municipal Livingston TX USA 30.68586
3 00V Meadow Lake Colorado Springs CO USA 38.94575
4 01G Perry-Warsaw Perry NY USA 42.74135
5 01J Hilliard Airpark Hilliard FL USA 30.68801
6 01M Tishomingo County Belmont MS USA 34.49167
7 02A Gragg-Wade Clanton AL USA 32.85049
8 02C Capitol Brookfield WI USA 43.08751
9 02G Columbiana County East Liverpool OH USA 40.67331
10 03D Memphis Memorial Memphis MO USA 40.44726
# ... with 3,366 more rows, and 1 more variables: long <dbl>Notice that because we used read_csv(), the data frame we received now prints nicely without having to use the head() function and does not clutter your screen.
5.3 Select
The select function is used to select columns.
- Select the destination, duration and distance columns (
dest,timeanddist)
flights %>%
select(dest, time, dist)# A tibble: 227,496 x 3
dest time dist
<chr> <int> <int>
1 DFW 40 224
2 DFW 45 224
3 DFW 48 224
4 DFW 39 224
5 DFW 44 224
6 DFW 45 224
7 DFW 43 224
8 DFW 40 224
9 DFW 41 224
10 DFW 45 224
# ... with 227,486 more rowsAdd the arrival delay (arr_delay) and departure delay (dep_delay) columns as well.
flights %>%
select(dest, time, dist, arr_delay, dep_delay)# A tibble: 227,496 x 5
dest time dist arr_delay dep_delay
<chr> <int> <int> <int> <int>
1 DFW 40 224 -10 0
2 DFW 45 224 -9 1
3 DFW 48 224 -8 -8
4 DFW 39 224 3 3
5 DFW 44 224 -3 5
6 DFW 45 224 -7 -1
7 DFW 43 224 -1 -1
8 DFW 40 224 -16 -5
9 DFW 41 224 44 43
10 DFW 45 224 43 43
# ... with 227,486 more rowsOther ways to do the same
flights %>%
select(dest, time, dist, ends_with("delay"))# A tibble: 227,496 x 5
dest time dist dep_delay arr_delay
<chr> <int> <int> <int> <int>
1 DFW 40 224 0 -10
2 DFW 45 224 1 -9
3 DFW 48 224 -8 -8
4 DFW 39 224 3 3
5 DFW 44 224 5 -3
6 DFW 45 224 -1 -7
7 DFW 43 224 -1 -1
8 DFW 40 224 -5 -16
9 DFW 41 224 43 44
10 DFW 45 224 43 43
# ... with 227,486 more rowsand …
flights %>%
select(dest, time, dist, contains("delay"))# A tibble: 227,496 x 5
dest time dist dep_delay arr_delay
<chr> <int> <int> <int> <int>
1 DFW 40 224 0 -10
2 DFW 45 224 1 -9
3 DFW 48 224 -8 -8
4 DFW 39 224 3 3
5 DFW 44 224 5 -3
6 DFW 45 224 -1 -7
7 DFW 43 224 -1 -1
8 DFW 40 224 -5 -16
9 DFW 41 224 43 44
10 DFW 45 224 43 43
# ... with 227,486 more rowsSelect all columns from date to arr
flights %>%
select(date:arr)# A tibble: 227,496 x 5
date hour minute dep arr
<dttm> <int> <int> <int> <int>
1 2011-01-01 12:00:00 14 0 1400 1500
2 2011-01-02 12:00:00 14 1 1401 1501
3 2011-01-03 12:00:00 13 52 1352 1502
4 2011-01-04 12:00:00 14 3 1403 1513
5 2011-01-05 12:00:00 14 5 1405 1507
6 2011-01-06 12:00:00 13 59 1359 1503
7 2011-01-07 12:00:00 13 59 1359 1509
8 2011-01-08 12:00:00 13 55 1355 1454
9 2011-01-09 12:00:00 14 43 1443 1554
10 2011-01-10 12:00:00 14 43 1443 1553
# ... with 227,486 more rowsSelect all except plane column using the minus sign
flights %>%
select(-plane)# A tibble: 227,496 x 13
date hour minute dep arr dep_delay arr_delay
<dttm> <int> <int> <int> <int> <int> <int>
1 2011-01-01 12:00:00 14 0 1400 1500 0 -10
2 2011-01-02 12:00:00 14 1 1401 1501 1 -9
3 2011-01-03 12:00:00 13 52 1352 1502 -8 -8
4 2011-01-04 12:00:00 14 3 1403 1513 3 3
5 2011-01-05 12:00:00 14 5 1405 1507 5 -3
6 2011-01-06 12:00:00 13 59 1359 1503 -1 -7
7 2011-01-07 12:00:00 13 59 1359 1509 -1 -1
8 2011-01-08 12:00:00 13 55 1355 1454 -5 -16
9 2011-01-09 12:00:00 14 43 1443 1554 43 44
10 2011-01-10 12:00:00 14 43 1443 1553 43 43
# ... with 227,486 more rows, and 6 more variables: carrier <chr>,
# flight <int>, dest <chr>, cancelled <int>, time <int>, dist <int>5.4 Filter
The filter() function returns rows with matching conditions. We can find all flights to Boston (BOS) like this:
flights %>%
filter(dest == "BOS")# A tibble: 1,752 x 14
date hour minute dep arr dep_delay arr_delay
<dttm> <int> <int> <int> <int> <int> <int>
1 2011-01-31 12:00:00 7 35 735 1220 0 4
2 2011-01-31 12:00:00 10 47 1047 1526 -3 -5
3 2011-01-31 12:00:00 13 5 1305 1746 0 -3
4 2011-01-31 12:00:00 19 1 1901 2332 6 -1
5 2011-01-31 12:00:00 15 50 1550 2012 0 -25
6 2011-01-30 12:00:00 10 46 1046 1518 -4 -8
7 2011-01-30 12:00:00 13 19 1319 1811 14 22
8 2011-01-30 12:00:00 19 9 1909 23 14 50
9 2011-01-30 12:00:00 15 53 1553 2030 3 -7
10 2011-01-29 12:00:00 7 40 740 1227 5 16
# ... with 1,742 more rows, and 7 more variables: carrier <chr>,
# flight <int>, dest <chr>, plane <chr>, cancelled <int>, time <int>,
# dist <int>Let’s build on the previous exercise and find all flights to Boston (BOS) and select only the dest, time, dist columns:
flights %>%
select(dest, time, dist) %>%
filter(dest == "BOS")# A tibble: 1,752 x 3
dest time dist
<chr> <int> <int>
1 BOS 195 1597
2 BOS 188 1597
3 BOS 190 1597
4 BOS 188 1597
5 BOS 180 1597
6 BOS 190 1597
7 BOS 185 1597
8 BOS 198 1597
9 BOS 194 1597
10 BOS 203 1597
# ... with 1,742 more rowsNow let’s do the filter first and then select the columns
flights %>%
filter(dest == "BOS") %>%
select(dest, time, dist) # A tibble: 1,752 x 3
dest time dist
<chr> <int> <int>
1 BOS 195 1597
2 BOS 188 1597
3 BOS 190 1597
4 BOS 188 1597
5 BOS 180 1597
6 BOS 190 1597
7 BOS 185 1597
8 BOS 198 1597
9 BOS 194 1597
10 BOS 203 1597
# ... with 1,742 more rowsIn this case the order doesn’t matter, but when using pipes make sure you understand that each function is executed in sequence and the results are then fed to the next one.
5.4.1 Exercise
Find all flights that match the following conditions:
- To SFO or OAK
- In January
- Delayed by more than an hour
- Departed between midnight and 5am
- Arrival delay more than twice the departure delay
Here’s a brief summary of operators you can use:
Comparison Operators
| Operator | Description | Example (assume x is 5) | Result |
|---|---|---|---|
| > | greater than | x > 5 | FALSE |
| >= | greater than or equal to | x >= 5 | TRUE |
| < | less than | x < 5 | FALSE |
| <= | less than or equal to | x <= 5 | TRUE |
| == | equal to | x == 5 | TRUE |
| != | not equal to | x != 5 | FALSE |
Logical Operators
| Operator | Description |
|---|---|
| ! | not |
| | | or |
| & | and |
Other Operators
| Operator | Description | Example (assume x is 5) | Result |
|---|---|---|---|
| %in% | check element in a vector | x %in% c(1, 3, 5, 7) x %in% c(2, 4, 6, 8) |
TRUE FALSE |
5.5 Arrange
The arrange() function is used to sort the rows based on one or more columns
flights %>%
arrange(dest)# A tibble: 227,496 x 14
date hour minute dep arr dep_delay arr_delay
<dttm> <int> <int> <int> <int> <int> <int>
1 2011-01-31 12:00:00 17 33 1733 1901 -2 -4
2 2011-01-30 12:00:00 17 50 1750 1913 15 8
3 2011-01-29 12:00:00 17 32 1732 1837 -3 -23
4 2011-01-28 12:00:00 17 33 1733 1848 -2 -17
5 2011-01-27 12:00:00 17 41 1741 1854 6 -11
6 2011-01-26 12:00:00 17 32 1732 1853 -3 -12
7 2011-01-25 12:00:00 17 29 1729 1858 -6 -7
8 2011-01-24 12:00:00 17 34 1734 1845 -1 -20
9 2011-01-23 12:00:00 17 35 1735 1853 0 -12
10 2011-01-22 12:00:00 17 33 1733 1843 -2 -17
# ... with 227,486 more rows, and 7 more variables: carrier <chr>,
# flight <int>, dest <chr>, plane <chr>, cancelled <int>, time <int>,
# dist <int>5.5.1 Exercise
- Order flights by departure date and time
- Which flights were most delayed?
- Which flights caught up the most time during flight?
5.6 Mutate
The mutate() function is used to create new variables.
Up until now we’ve only been examining the dataset but haven’t made any changes to it. All our functions so far have simply displayed the results on screen but haven’t created or modified existing variables. Let’s see how we can create a new variable called speed based on the distance and duration in the flights dataframe.
In this exercise we’re adding a new variable to an existing dataframe so we’ll just overwrite the flights variable with the one that has a speed column
flights <- flights %>%
mutate(speed = dist / (time / 60))5.6.1 Exercise
- Add a variable to show how much time was made up (or lost) during flight
5.7 Summarise
Let’s count the number of flights departing each day.
flights %>%
group_by(date) %>%
summarise(count = n()) # A tibble: 365 x 2
date count
<dttm> <int>
1 2011-01-01 12:00:00 552
2 2011-01-02 12:00:00 678
3 2011-01-03 12:00:00 702
4 2011-01-04 12:00:00 583
5 2011-01-05 12:00:00 590
6 2011-01-06 12:00:00 660
7 2011-01-07 12:00:00 661
8 2011-01-08 12:00:00 500
9 2011-01-09 12:00:00 602
10 2011-01-10 12:00:00 659
# ... with 355 more rowsHere’s a nice little trick. You can use View() to look at the results of a pipe operation without creating new variables.
flights %>%
group_by(date) %>%
summarise(count = n()) %>%
View()Of course, often times we’d want to save the summary in a variable for further analysis.
Let’s find the average departure delay for each destination
delays <- flights %>%
group_by(dest) %>%
summarise(mean = mean(dep_delay))
delays# A tibble: 116 x 2
dest mean
<chr> <dbl>
1 ABQ NA
2 AEX NA
3 AGS 10.000
4 AMA NA
5 ANC 24.952
6 ASE NA
7 ATL NA
8 AUS NA
9 AVL NA
10 BFL NA
# ... with 106 more rows5.7.1 Exercise
- What’s wrong with the results above, and how would you fix the problem?
- Can you think of using filter to solve the problem?
- Use help to find out two other ways to do summarize/n combination in dplyr.
- How many different destinations can you fly to from Houston?
- Which destinations have the highest average delays?
- Which flights (carrier + flight number) happen everyday and where do they fly?
- How do delays (of non-cancelled flights) vary over the course of a day?
5.8 Unite
The unite function is useful for combining multiple columns together. In the example below, we join the carrier and flight to create a unique flight_id column.
flights %>%
unite(flight_id, carrier, flight, sep = "-", remove = FALSE) %>%
select(date, carrier, flight, flight_id)# A tibble: 227,496 x 4
date carrier flight flight_id
* <dttm> <chr> <int> <chr>
1 2011-01-01 12:00:00 AA 428 AA-428
2 2011-01-02 12:00:00 AA 428 AA-428
3 2011-01-03 12:00:00 AA 428 AA-428
4 2011-01-04 12:00:00 AA 428 AA-428
5 2011-01-05 12:00:00 AA 428 AA-428
6 2011-01-06 12:00:00 AA 428 AA-428
7 2011-01-07 12:00:00 AA 428 AA-428
8 2011-01-08 12:00:00 AA 428 AA-428
9 2011-01-09 12:00:00 AA 428 AA-428
10 2011-01-10 12:00:00 AA 428 AA-428
# ... with 227,486 more rows5.9 Separate
The separate function works the other way around by splitting a single column into multiple columns. Let’s split the date column into separate date and time columns.
flights %>%
separate(date, c("date", "time"), sep = " ")# A tibble: 227,496 x 16
date time hour minute dep arr dep_delay arr_delay
* <chr> <chr> <int> <int> <int> <int> <int> <int>
1 2011-01-01 12:00:00 14 0 1400 1500 0 -10
2 2011-01-02 12:00:00 14 1 1401 1501 1 -9
3 2011-01-03 12:00:00 13 52 1352 1502 -8 -8
4 2011-01-04 12:00:00 14 3 1403 1513 3 3
5 2011-01-05 12:00:00 14 5 1405 1507 5 -3
6 2011-01-06 12:00:00 13 59 1359 1503 -1 -7
7 2011-01-07 12:00:00 13 59 1359 1509 -1 -1
8 2011-01-08 12:00:00 13 55 1355 1454 -5 -16
9 2011-01-09 12:00:00 14 43 1443 1554 43 44
10 2011-01-10 12:00:00 14 43 1443 1553 43 43
# ... with 227,486 more rows, and 8 more variables: carrier <chr>,
# flight <int>, dest <chr>, plane <chr>, cancelled <int>, time <int>,
# dist <int>, speed <dbl>5.9.1 Exercise
- Split the
datecolumn intoyear,month, anddaycolumns - Ensure that the
year,month, anddaycolumns are of type integer (NOT character)- HINT: Use online help for
separatefor an easy way to do this
- HINT: Use online help for