4 Hands-on Tutorial
Let’s start by loading the required packages:
library(foreign)
library(Zelig)
library(texreg)
library(lmtest)
library(dplyr)Clear the environment
rm(list = ls())4.1 Application to British Election Study Dataset
We use a subset of the 2005 face-to-face British post election study to explain turnout.
Disclaimer: We use a slightly modified version of the data set. For your own research please visit the British Election Study website and download the original dataset.
You can download the dataset and codebook from the links below:
Most of the variable names in the dataset are self explanatory, but ones that need some clarification are listed below:
| Variable | Description | Range |
|---|---|---|
| Turnout | Turnout at 2005 Brit election | No (0); Yes (1) |
| Gender | R’s gender | 1 (male); 0 (female) |
| LeftRightSelf | R’s self placement on left-right | 1 (left) - 11 (right) |
| CivicDutyIndex | Sum of scores on CivicDuty1-7 | high values mean high civic duty |
| polinfoindex | Correctly answered knowledge questions | 0 (low) - 8 (high) |
| edu* | yrs of education | binary |
| in.school | R still in school | binary |
| in.uni | R attends university | binary |
4.2 Loading Data
bes <- read.dta("bes.dta")Let’s convert the Gender variable to a factor to help us with the interpretation of the results.
bes$Gender <- factor(bes$Gender, levels = c(0, 1), labels = c("Female", "Male"))Now take a look at the first few observations to see what the dataset looks like
head(bes)## cs_id Turnout Vote2001 Income Age Gender PartyID Influence Attention
## 1 1 0 1 4 76 Female 1 1 8
## 2 2 1 1 5 32 Male 0 3 8
## 3 3 1 NA NA NA <NA> NA NA NA
## 4 4 0 1 1 35 Female 0 1 1
## 5 5 1 1 7 56 Male 0 1 9
## 6 6 1 1 4 76 Female 1 4 8
## Telephone LeftrightSelf CivicDutyIndex polinfoindex edu15 edu16 edu17
## 1 1 7 20 7 1 0 0
## 2 1 6 15 5 0 1 0
## 3 NA NA NA NA NA NA NA
## 4 0 5 26 1 0 1 0
## 5 1 9 16 7 0 0 1
## 6 1 8 16 4 0 1 0
## edu18 edu19plus in_school in_uni CivicDutyScores
## 1 0 0 0 0 -0.6331136
## 2 0 0 0 0 1.4794579
## 3 NA NA NA NA NA
## 4 0 0 0 0 -2.1466281
## 5 0 0 0 0 1.0324940
## 6 0 0 0 0 0.3658024We have a number of missing values. Let’s remove them from the dataset but we want to make sure we only remove observations when the variables we are interested in are missing. We’ll follow the same procedure we used in week 5 for removing NA’s.
While this method might seem tedious, it ensures that we’re not dropping observations unnecessarily.
bes <- filter(bes,
!is.na(Turnout),
!is.na(Income),
!is.na(polinfoindex),
!is.na(Gender),
!is.na(edu15),
!is.na(edu17),
!is.na(edu18),
!is.na(edu19plus),
!is.na(in_school),
!is.na(in_uni))4.3 Regression with a Binary Dependent Variable
We use the generalized linear model function glm() to estimate a logistic regression. The syntax is very similar to other regression functions we’re already familiar with, for example lm() and plm(). The glm() function can be used to estimate many different models. We tell glm() that we’ve binary dependent variable and we want to use the cumulative logistic link function using the family = binomial(link = "logit") argument:
model1 <- glm(Turnout ~ Income + polinfoindex + Gender +
edu15 + edu17 + edu18 + edu19plus + in_school + in_uni,
family = binomial(link = "logit"),
data = bes)
screenreg(model1)##
## ============================
## Model 1
## ----------------------------
## (Intercept) -1.14 ***
## (0.15)
## Income 0.03
## (0.02)
## polinfoindex 0.38 ***
## (0.02)
## GenderMale -0.35 ***
## (0.08)
## edu15 0.38 ***
## (0.10)
## edu17 0.46 **
## (0.15)
## edu18 0.11
## (0.14)
## edu19plus 0.24 *
## (0.12)
## in_school 0.15
## (0.39)
## in_uni -0.72 **
## (0.25)
## ----------------------------
## AIC 4401.20
## BIC 4464.53
## Log Likelihood -2190.60
## Deviance 4381.20
## Num. obs. 4161
## ============================
## *** p < 0.001, ** p < 0.01, * p < 0.054.4 Model Quality
To assess the predictive accuracy of our model we will check the percentage of cases that it correctly predicts. Let’s look the turnout data first. According to the codebook, 0 means the person did not vote, and 1 means they voted.
table(bes$Turnout) ##
## 0 1
## 1079 3082If we look at the mean of Turnout we will see that is 0.74. That means 74.07% of the respondents said that they turned out to vote. If you predict for every respondent that they voted, you will be right for 74.07% of the people. That is the naive guess and the benchmark for our model. If we predict more than 74.07% of cases correctly our model adds value.
Below we will estimate predicted probabilities for each observation. That is, the probability our model assigns that a respondent will turn out to vote for every person in our data. To do so we use the predict() function with the following the usage syntax:
predict(model, type = "response")Type help(predict.glm) for information on all arguments.
predicted_probs <- predict(model1, type = "response")Now that we have assigned probabilities to people turning out to vote, we have to translate those into outcomes. Turnout is binary. A straightforward way would be to say: we predict that all people with a predicted probability above 50% vote and all with predicted probabilities below or equal to 50% abstain.
Using the 50% threshold, we create a new variable expected_values that is 1 if our predicted probability is larger than 0.5 and 0 otherwise.
expected <- as.numeric(predicted_probs > 0.5)NOTE: The condition predicted_probs > 0.5 gives us FASLE/TRUE, but since our dataset uses 0/1 for the Turnout variable, we convert it to a numeric value using as.numeric() function.
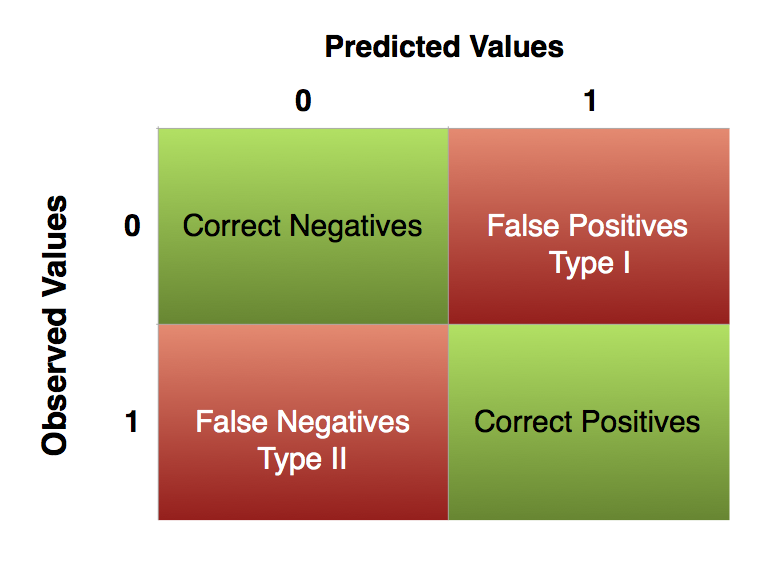
All we have to do now is to compare our expected values of turnout against the actually observed values of turnout. We want our predictions to coincide with the actually observed outcomes. But we need to be aware of two types of errors we can make:
| - A type I error is a false positive. It is like crying wolf when there is nothing there (we mistakenly reject a true null hypothesis). - A type II error is a false negative. It is like not noticing the wolf and finding all your sheep dead the next morning (we fail to reject a false null hypothesis). |
 |
The threshold that we set is directly related to the proportion of type I to type II errors. Increasing the threshold will reduce the number of false positives but increase the number of false negatives and vice versa. The default choice is a threshold of 0.5. However, you may imagine situations where one type of error is more costly than the other. For example, given the cost of civil wars, a model predicting civil war may focus on reducing false negatives at the cost of a larger fraction of false positives.
We proceed by producing a table of predictions against actual outcomes. With that we will calculate the percentage of correctly predicted cases and compare that to the naive guess. We have the actually observed cases in our dependent variable (Turnout). The table is just a frequency table. The percentage of correctly predicted cases is simply the sum of correctly predicted cases over the number of cases.
observed <- bes$Turnout
outcome <- table(observed,expected)
outcome## expected
## observed 0 1
## 0 160 919
## 1 108 2974Now let’s find out how many we correctly predicted and how many we got wrong. You can manually add the numbers if you want, but it’s simple enough to take the values out of the 2x2 table:
- Correct negatives are in row
1, column1 - Correct positives are in row
2, column2 - All others are incorrect
(outcome[1,1] + outcome[2,2]) / sum(outcome)## [1] 0.7531843Now let’s remember what the actual turnout was:
table(bes$Turnout)##
## 0 1
## 1079 3082In order to calculate the naive guess, we simply divide the mode by the total number of observations
3082 / (1079 + 3082)## [1] 0.7406873You can see that our model outperforms the naive guess slightly. The more lopsided the distribution of your binary dependent variable, the harder it is to build a successful model.
4.4.1 Joint hypothesis testing
We will add two more explanatory variables to our model: Influence and Age. Influence corresponds to a theory we want to test while Age is a socio-economic control variable.
We want to test two theories: the rational voter model and the resource theory.
Influence operationalises a part of the rational voter theory. In that theory citizens are more likely to turnout the more they belive that their vote matters. The variable
Influencemeasures the subjective feeling of being able to influence politics.The variables
Incomeandpolinfoindexcorrespond to a second theory which states that people who have more cognitive and material resources are more likely to participate in politics.
Depending on whether the coefficients corresponding to the respective theories are significant or not, we can say something about whether these theories help to explain turnout.
The remaining variables for gender, education and the added variable Age are socio-economic controls. We added age because previous research has shown that political participation changes with the life cycle.
model2 <- glm(Turnout ~ Income + polinfoindex + Influence + Gender + Age +
edu15 + edu17 + edu18 + edu19plus + in_school + in_uni,
family = binomial(link = "logit"), data = bes)
screenreg(list(model1, model2))##
## ==========================================
## Model 1 Model 2
## ------------------------------------------
## (Intercept) -1.14 *** -3.90 ***
## (0.15) (0.22)
## Income 0.03 0.15 ***
## (0.02) (0.02)
## polinfoindex 0.38 *** 0.25 ***
## (0.02) (0.02)
## GenderMale -0.35 *** -0.36 ***
## (0.08) (0.08)
## edu15 0.38 *** -0.34 **
## (0.10) (0.11)
## edu17 0.46 ** 0.36 *
## (0.15) (0.16)
## edu18 0.11 0.14
## (0.14) (0.15)
## edu19plus 0.24 * 0.01
## (0.12) (0.13)
## in_school 0.15 1.13 **
## (0.39) (0.40)
## in_uni -0.72 ** -0.05
## (0.25) (0.27)
## Influence 0.21 ***
## (0.02)
## Age 0.05 ***
## (0.00)
## ------------------------------------------
## AIC 4401.20 4003.90
## BIC 4464.53 4079.90
## Log Likelihood -2190.60 -1989.95
## Deviance 4381.20 3979.90
## Num. obs. 4161 4161
## ==========================================
## *** p < 0.001, ** p < 0.01, * p < 0.05The variables corresponding to the resource theory are Income and polinfoindex. In our model 2 (the one we interpret), both more income and more interest in politics are related to a higher probability to turn out to vote. That is in line with the theory. Interestingly, income was previously insignificant in model 1. It is quite likely that model 1 suffered from omitted variable bias.
As the rational voter model predicts, a higher subjective probability to cast a decisive vote, which we crudly proxy by the feeling to be able to influence politics, does correspond to a higher probability to vote as indicated by the positive significant effect of our Influence variable.
We will test if model 2 does better at predicting turnout than model 1. We use the likelihood ratio test. This is warranted because we added two variables and corresponds to the F-test in the OLS models estimated before. You can see values for the logged likelihood in the regression table. You cannot in general say whether a value for the likelihood is small or large but you can use it to compare models that are based on the same sample. A larger log-likelihood is better. Looking at the regression table we see that the log-likelihood is larger in model 2 than in model 1.
We use the lrtest() function from the lmtest package to test whether that difference is statistically significant. The syntax is the following:
lrtest(model1, model2)## Likelihood ratio test
##
## Model 1: Turnout ~ Income + polinfoindex + Gender + edu15 + edu17 + edu18 +
## edu19plus + in_school + in_uni
## Model 2: Turnout ~ Income + polinfoindex + Influence + Gender + Age +
## edu15 + edu17 + edu18 + edu19plus + in_school + in_uni
## #Df LogLik Df Chisq Pr(>Chisq)
## 1 10 -2190.6
## 2 12 -1990.0 2 401.3 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The p-value in the likelihood ratio test is smaller than 0.05. Therefore, the difference between the two log-likelihoods is statistically significant which means that model 2 is better at explaining turnout.
Now let’s see if AIC and BIC agree.
AIC(model1, model2)## df AIC
## model1 10 4401.200
## model2 12 4003.901BIC(model1, model2) ## df BIC
## model1 10 4464.535
## model2 12 4079.903According to both AIC and BIC, model 2 has a better fit.
4.5 Interpretation with Zelig
Since we cannot directly estimate the marginal effects of the independent variables from a logistic regression model, we use Zelig to help us with the interpretation. We pick meaningful scenarios and predict the probability that a person will vote based on the scenarios. What are meaningful scenarios? A meaningful scenario is a set of covariate values that corresponds to some case that is interesting in reality. For example, you may want to compare a women with 18 years of education to a man with 18 years of education while keeping all other variables at their means, medians or modes.
First, we re-estimate our previous model using Zelig.
NOTE: Since we’re estimating a logistic regression model, we use model = "logit" instead of model = "ls" like we’ve done in the past.
z.out <- zelig(Turnout ~ Income + polinfoindex + Influence + Gender + Age +
edu15 + edu17 + edu18 + edu19plus + in_school + in_uni,
model = "logit",
data = bes)## How to cite this model in Zelig:
## R Core Team. 2007.
## logit: Logistic Regression for Dichotomous Dependent Variables
## in Christine Choirat, Christopher Gandrud, James Honaker, Kosuke Imai, Gary King, and Olivia Lau,
## "Zelig: Everyone's Statistical Software," http://zeligproject.org/In order to compare the average women with 18 years of education to the average man with 18 years of education, Gender to either Male or Female, edu18 to 1 and all other binary variables to their modes, ordinally scaled variables to their medians and interval scaled variables to their means.
x.male <- setx(z.out,
Gender = "Male", edu18 = 1,
Age = mean(bes$Age),
Income = mean(bes$Income),
polinfoindex = mean(bes$polinfoindex),
Influence = mean(bes$Influence),
edu15 = 0, edu17 = 0, edu19plus = 0, in_school = 0, in_uni = 0)
x.female <- setx(z.out, Gender = "Female", edu18 = 1,
Age = mean(bes$Age),
Income = mean(bes$Income),
polinfoindex = mean(bes$polinfoindex),
Influence = mean(bes$Influence),
edu15 = 0, edu17 = 0, edu19plus = 0, in_school = 0, in_uni = 0)
s.out <- sim(z.out, x.male, x1 = x.female)
summary(s.out)##
## sim x :
## -----
## ev
## mean sd 50% 2.5% 97.5%
## [1,] 0.7845004 0.02570278 0.7856962 0.7319866 0.8313563
## pv
## 0 1
## [1,] 0.228 0.772
##
## sim x1 :
## -----
## ev
## mean sd 50% 2.5% 97.5%
## [1,] 0.8379307 0.01968942 0.8392759 0.7976236 0.8730706
## pv
## 0 1
## [1,] 0.169 0.831
## fd
## mean sd 50% 2.5% 97.5%
## [1,] 0.05343038 0.01391021 0.05238642 0.02780798 0.08104585If you’re not familiar with how to interpret Zelig simulation summary, then click at the link below for an annotated example:
For the average woman (in our sample) with 18 years of education, we predict a probability of 84% that she will vote. Our uncertainty is plus and minus 4% on the 95% confidence level. Note that we’ve rounded up the numbers just to simplify the interpretation.
For her male counterpart, we predict the probability of turnout to be 78% (plus and minus 5% based on the 95% confidence interval). Is the difference between them statistically significant or put differently is our hypothetical woman more likely to vote than our hypothetical man?
To check that we look at the first difference. The difference is 5% percentage points on average and between 3 percentage points and 8 percentage points based on the 95% confidence interval.
Our next step will be to compare two groups like men and women while varying another continuous variable from lowest to highest. We use income here. So, we set a sequence for income, vary gender and keep every other variable constant at its appropriate measure of central tendency.
Let’s see what the range of Income variable is:
range(bes$Income)## [1] 1 13Income ranges from 1 to 13 in our sample so we can just say Income = 1:13 or use the seq() function as shown below:
x.male <- setx(z.out,
Gender = "Male", edu18 = 1,
Age = mean(bes$Age),
Income = seq(1, 13),
polinfoindex = mean(bes$polinfoindex),
Influence = mean(bes$Influence),
edu15 = 0, edu17 = 0, edu19plus = 0, in_school = 0, in_uni = 0)
x.female <- setx(z.out, Gender = "Female", edu18 = 1,
Age = mean(bes$Age),
Income = seq(1, 13),
polinfoindex = mean(bes$polinfoindex),
Influence = mean(bes$Influence),
edu15 = 0, edu17 = 0, edu19plus = 0, in_school = 0, in_uni = 0)
s.out <- sim(z.out, x.male, x1 = x.female)Now we can plot the confidence interval for the two groups:
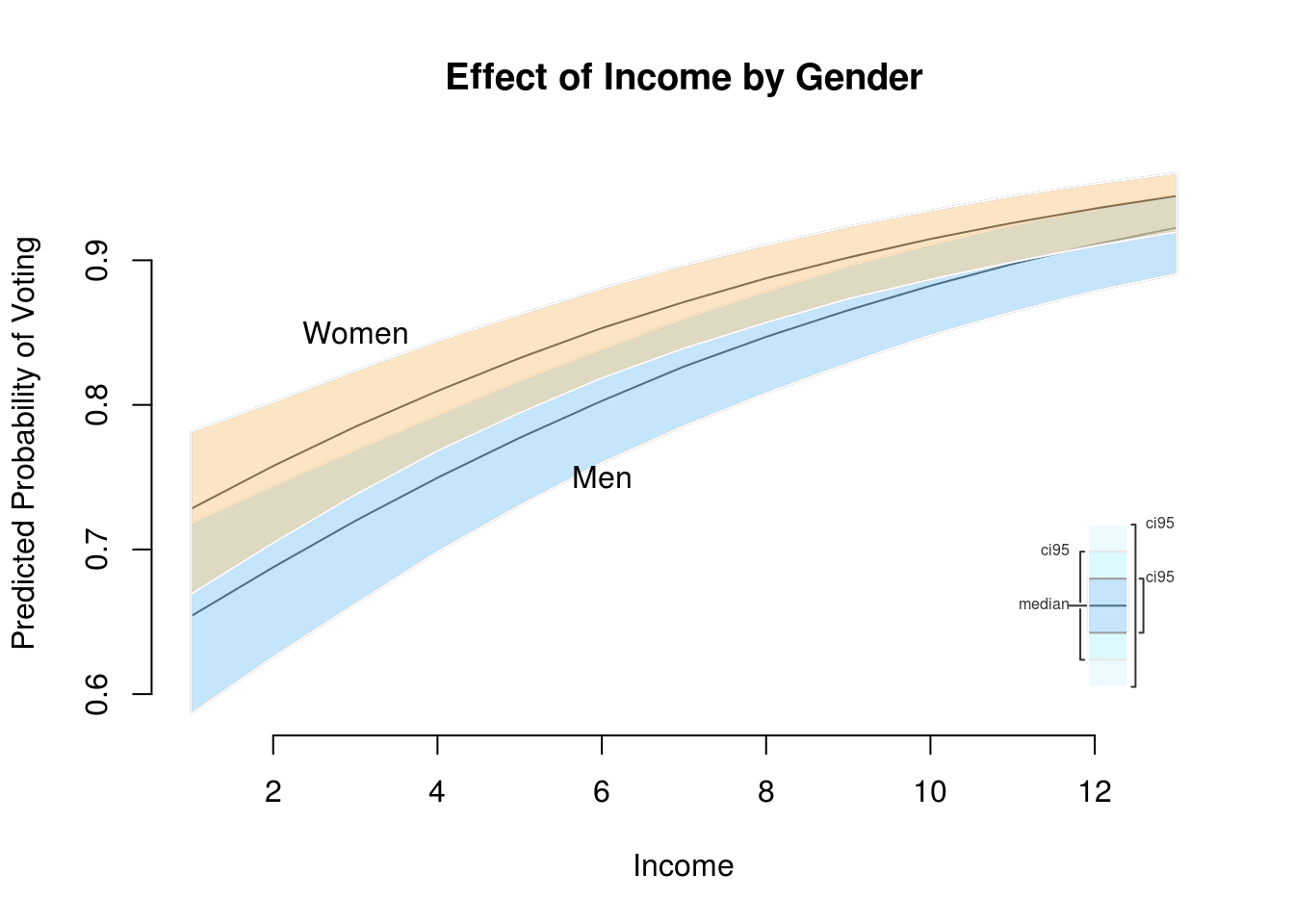
ci.plot(s.out,
ci = 95,
xlab = "Income",
ylab = "Predicted Probability of Voting",
main = "Effect of Income by Gender")
# add labels manually
# NOTE: the x and y values below are just coordinates on the plot, you can change
# them based on where you want the labels placed
text(x = 3, y = .85, labels = "Women")
text(x = 6, y = .75, labels = "Men")